
Index
DB 시스템의 목적
DB : 데이터의 집합(활용하기 쉽도록)
DBMS : 데이터를 관리하는 프로그램의 집합
최대한 유저에게 필요한 정보만 제공하는데 초점
DB를 만들어야 할때
예를 들어 대학에서 DB를 구축한다고 가정하자.
•
학생 학업 과목 ….
학생들에게 서비스를 제공해야 할 때 이 데이터 간의 관계 또한 필요함.
•
학생이 수강하는 과목
•
과목의 담당교수
•
교수가 지도하는 학생
계속해서 필요한 정보들이 발생하고 이에 맞는 프로그램의 작성이 필요함.
File Systems의 결점
Data Redundancy and inconsistency

같은 데이터를 값이 하나가 다르다는 이유로 많은 데이터를 중복으로 다시 넣어줘야하는 것을 중복성(Redundancy)이라고 한다.
어느 한쪽에서만 데이터를 변경할 때, 다른 곳에서 값이 반영되지 않은 문제를 비일관성(Inconsistent)라고 한다.
Difficulty in accessing Data
Data isolation
필요한 데이터가 여러 파일에 흩어지거나 포맷이 달라 관리 난이도가 올라갈 수 있다.
Integrity Problems
????
Atomicity Problems
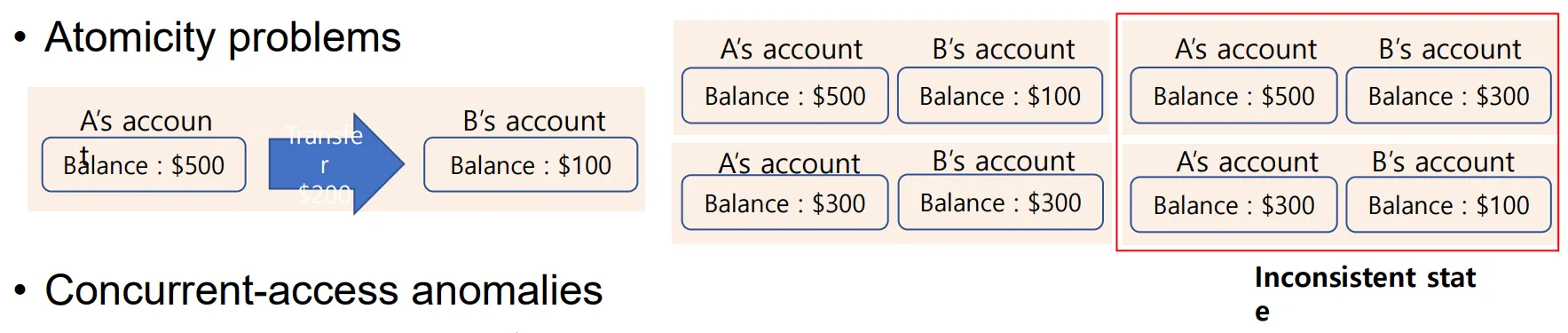
해당 명령의 결과로 나올 수 있는 경우의 수는
1.
아무 일도 일어나지 않는다.(0 state)
2.
A -= 200, B += 200. 모든 과정이 완료되었다. (1 state)
3.
A의 돈이 감소하지 않았으나, B의 돈이 증가한 경우
4.
A의 돈은 감소했으나, B의 돈이 증가하지 않은 경우
로 될 수 있다.
Concurrent-access anomalies
동시 접속 문제
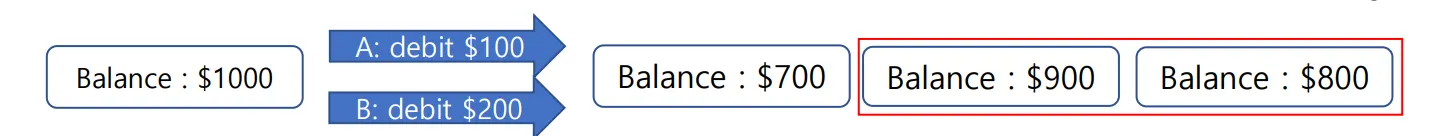
두 클라이언트 입장에서 모두 잔고가 1000$라고 보인다.
•
A가 먼저 100불을 인출해 900$를 덮어씌운다.
◦
B도 1000불에서 200불을 빼서 800$을 덮어씌운다.
•
B가 먼저 200불을 인출해 800$을 덮어씌운다.
◦
A도 1000불에서 100불을 빼서 900$을 덮어씌운다.
DB는 여러 사용자가 동시에 접근하는 것에 대한 순서를 통제하는 역할을 해준다.
Security Problems
DB시스템을 이용하는 모든 유저들은 데이터에 대한 권한을 달리해줘야 한다.
•
파일 시스템의 경우, 유저가 파일 안의 모든 데이터에 접근 가능함.
+) Atomicity VS Consistency
데이터의 Atomicity가 보장될 경우, Consistency또한 보장된다.
Atomicity는 크게 : 연산의 특징
Consistency는 : 데이터의 특징
+) Atomicity VS Concurrent-Access
•
Concurrent-Access
각각의 스레드가 로컬밸류에서 일을 하는 개념?
Atomicity와 Concurrent-Access를 모두 만족하면 Consistency를 달성할 수 있다.
Data Models
데이터를 표현하기 위한 개념적인 툴
•
데이터
•
데이터간의 관계
•
데이터의 Semantics
•
Consistency Constraints
를 Data Models로 표현할 수 있다.
모델을 쓰니까 데이터가 간단해져서 알아보기 편해짐
모델의 사용 이유
현실 세계의 일부분은 관리하거나 실험할 때 유용함. (대표적으로 비용 다운적인 면에서)

복잡한 정보를 정리하고 필요한 범위의 데이터만 제공해주는 것이 모델의 역할.
모델의 종류
•
Relational model (Entity-Relationship data model)
엔티티와 엔티티간의 관계를 나타내는 모델
•
Object-based data models
•
Semi-structured data model (XML)
Data Abstraction
데이터의 추상화를 통해 데이터의 복잡한 정보를 가리고 필요한 정보를 쉽게 받아갈 수 있음.
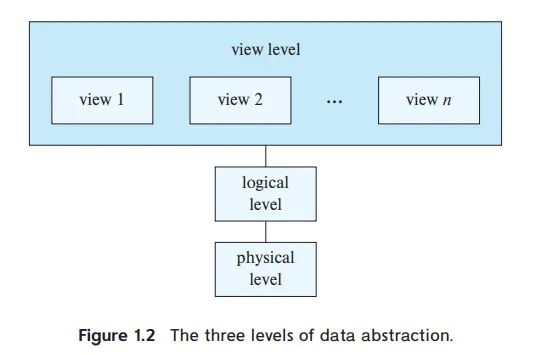
•
Physical Level (실제 저장되는 레벨)
◦
index structure(B+-tree, 해시테이블), Slotted page (Basically DRAM)
▪
index structure : 실제 데이터가 어디에 저장되어있는지 알려주는 일련의 목차 개념
▪
Slotted Page : 실제 데이터를 저장하기 위한 페이지 주소
•
Logical Level (논리적으로 한 차례 정리되는 곳)
◦
DB
type instructor = record
ID : char (5);
name : char (20);
dept name : char (20);
salary : numeric (8,2);
end;
C
복사
•
View level (열람하는 레벨, 고단계 추상화 레벨)
◦
각 유저는 자신에게 허락되는 권한만큼만 정보에 엑세스가 가능함.
◦
뷰는 전체를 다 보여줄 수 있지만, 해당 유저에게 허락되는 양의 정보만큼 보여준다.
Instances and Schemas
type instructor = record
ID : char (5);
name : char (20);
dept name : char (20);
salary : numeric (8,2);
end;
C
복사
Schema : 뼈대 → 스켈레톤
Instance : 실제 내용 → 살
Physical data independence
•
Physical Schema를 Logical Schema를 변경하지 않은 채로 변경할 수 있는 능력? 상태?
App은 Logical Schema에 기반한다. → Physical Schema의 구조가 어떤지는 크게 관심없음.
DB 내부에서는 Logical Schema는 유지되나, Physical Schema에 대해서는 필요할 경우 구조를 바꿀 수 있다. → 그렇게 해도 유저는 동일한 정보를 얻을 수 있다.
Relation(Table) → Logical Level은 유지되나, Physical Schema는 바뀔 수 있다.
Next Chapter