
previous chapter
Introduction to Relational Model
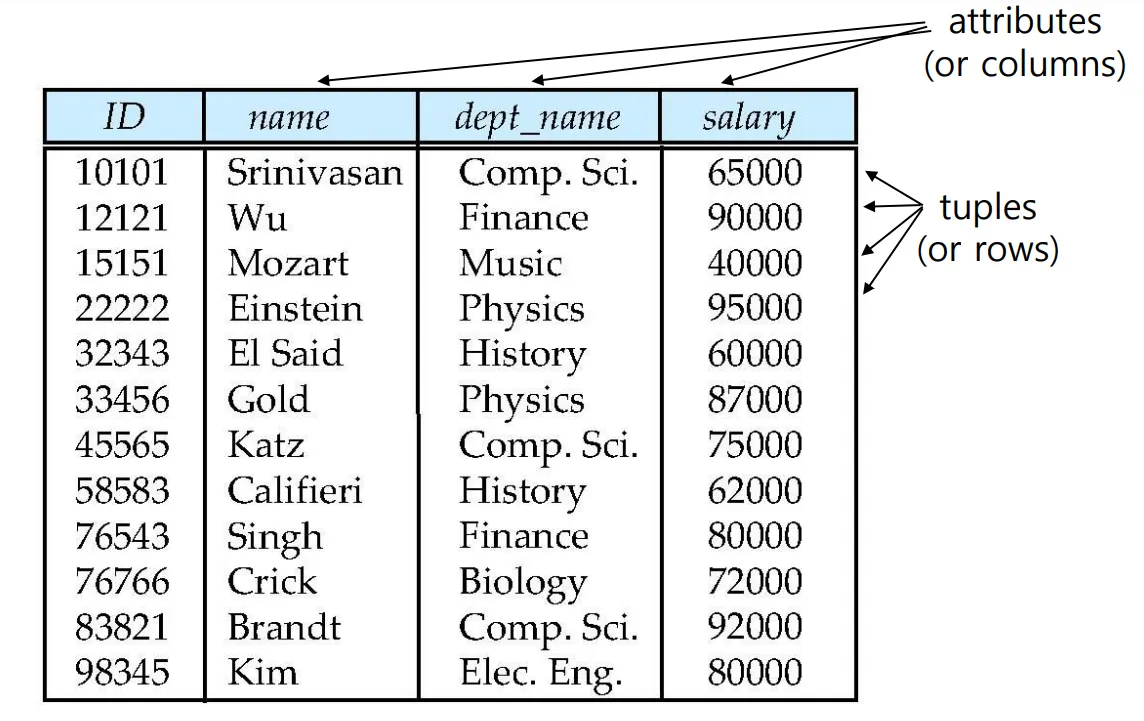
Attribute Types
각각의 Attribute에는 Domain(Di)이라는 게 존재하며, Attribute는 Domain의 제약 안에서 구성이 가능하다.
•
Di : 8자리 Positive value
Attribute 값은 atomic하기를 요구된다.
null값은 Special 밸류 취급되며, 도메인의 멤버에 포함된다.
Relation Schema and Instance
A : Attributes
R : Relation Schema
•
instructor = (ID, name, dept_name, salary)
인스턴스 r이 Schema R에 의해 정의될 경우 r(R)이라고 나타낼 수 있다.
Relations는 순서가 정해져있지 않음
일반적으로 tuples는 들어온 순서대로임.
즉, 정렬되지 않는다.
반면 Relation 은 tuple 구조이기 때문에 Attribute의 순서를 잘 지켜야 한다.
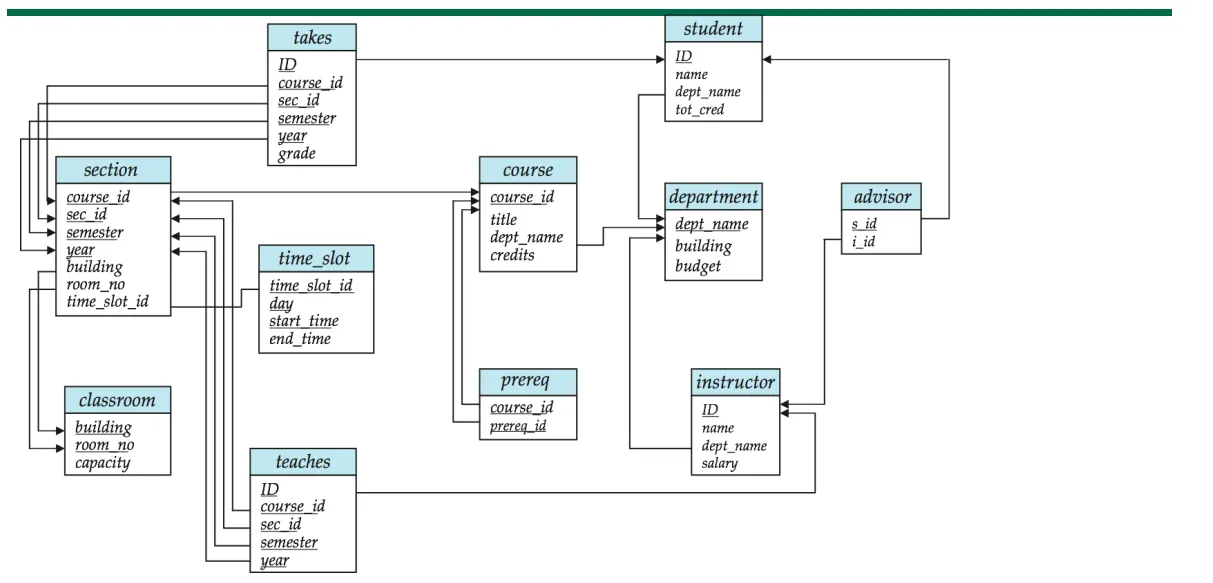
Database
데이터베이스는 복수의 Relation으로 이루어진다.
•
EX ) 대학 DB는 다음과 같은 Relation으로 이루어진다.
◦
Instructor
◦
Student
◦
Advisor
구린 디자인
•
univ(instructor -ID, name, dept_name, salary, student_ID, ..)
◦
한 곳에 다 때려박는 건 좋지 않음
Keys
Superkey : 데이터를 구별할 수 있는 핵심 키
•
ID는 모두가 Identical한 숫자를 부여받으므로 superkey라고 할 수 있다.
•
ID + 이름의 Relation이 있을 때 ID가 있기 때문에 superkey라고 볼 수 있다.
결국 ID+@의 조합으로 여러가지 슈퍼키가 만들어질 수 있는데
SuperKey가 될 수 있는 최소의 조건은 결국 ID일 것이다.
이를 Candidate Key라고 한다.
Candidate Key 중 하나가 Primary Key로 선택받을 수 있다.
Foreign Key : 복수의 테이블에 중복으로 존재하는 Key
2023-03-09 수업 정리
Relational Query Languages
Relation을 바탕으로 Relation 모델이 존재할 때, Relation을 대상으로 쓸 수 있는 공용의 언어
SQL(Structured Query Language)
•
관계 대수
•
Tuple 관계 calculus (x)
•
Domain 관계 calculus (x)
관계 연산자
•
Relational Query Languages는 6개의 관계 연산자를 사용
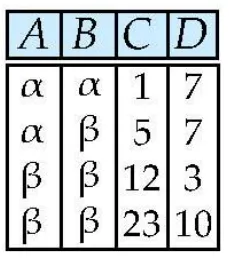
Selection of tuples : σ
•
Relation r:
◦
A = B && D > 5 인 tuples을 찾아라
→
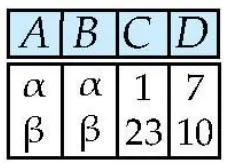
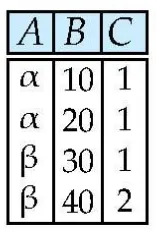
Projection of attributes : ∏
필요한 Column만 뽑아낼 수 있음
중복되는 데이터를 간략화함(?)
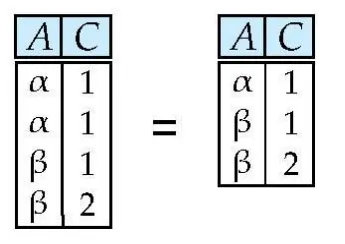
Union of two relations : ∪
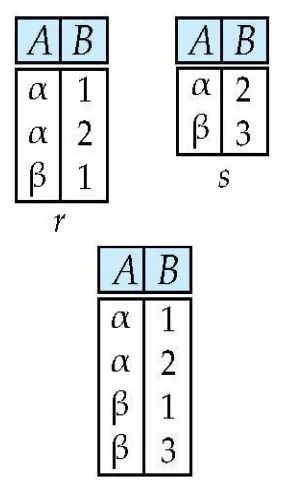
Set difference of two relations : -
•
교집합에 해당하는 부분은 제거, 나머지는 그냥 없던거로
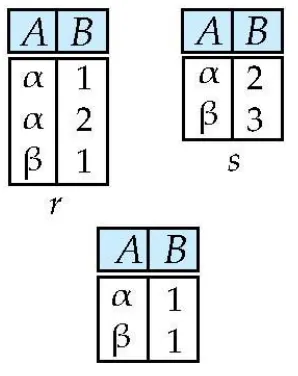
Set Intersection of two relations : ∩
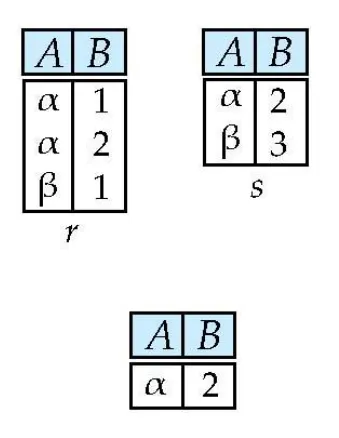
Joining two relations - Cartesian Product : ×
r과 s의 조합

키가 겹치는 경우에 대해서도 생각할 것!
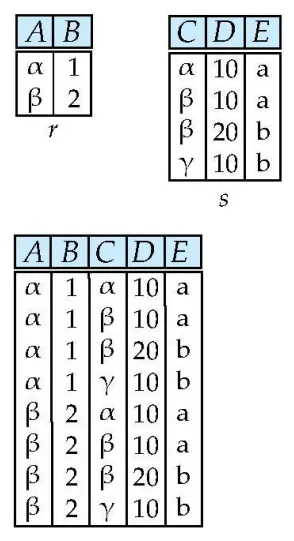
Joining two relations - Natural Join : ⋈
관계 r와 s는 자기만의 column이 있다고 가정하자.
아래 그림에서 r과 s의 공통 column은 B, D이다.
•
r의 B,D(1) = s의 B,D(1) = B,D(4) = s의 B,D(3) 이다.
◦
A,C,E에서 값을 가져온다.
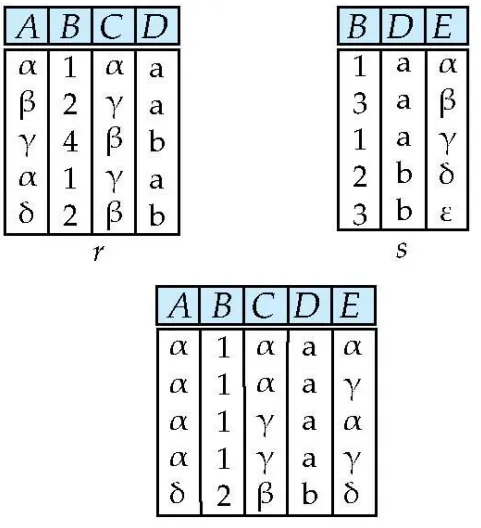
Natural Join Example
Relational Operation의 연산 결과 후, 중복되는 값은 생략하는게 원칙.
→다만, SQL에서는 (일반적으로) 중복된 값도 다 보여준다.
The Rename Operation ρ
복잡한 Relation Operation을 하나의 변수처럼 치환해주는 연산자.
Next Chapter