
Previous chapter
The Rename Operation
old-name as new-name
SQL
복사
as 키워드는 옵션이며, 생략 가능하다.
instructor as T == instructor T
SQL
복사
그래도 헷갈리지 않게 하기 위해 가급적 as를 추가하자.
String Operations
SQL은 string-matching 오퍼레이터를 제공하고 있음
•
percent(%) : any substring. → include length == 0
Intro% #Intro로 시작하는 모든 문자열
%Comp% #Comp를 서브스트링으로 가지는 모든 문자열
SQL
복사
•
underscore(_) : Any String.
_ _ _#(실제로는 붙여쓰세요...) 정확히 세 개의 문자로 이루어진 문자열
_ _ _% #세개 이상의 문자열과 일치한다.
SQL
복사
이 오퍼레이터를 기본으로 like 비교 오퍼레이터를 사용하여 표현한다.
•
“department의 dept_name에 ‘Watson’이라는 부분 문자열을 포함하는 모든 이름을 구하라.”
select dept_name
from department
where building like "%Watson%";
SQL
복사
•
데이터에 ‘%’가 들어가면 어떻게 하나요?

escape 오퍼레이터를 통해 스페셜 오퍼레이터와의 구분이 가능합니다.
like 'ab\%cd%' escape '\' "#ab%cd로 시작하는 모든 문자열과 일치한다.'
like 'ab\\cd%' escape '\' "#ab\cd로 시작하는 모든 문자열과 일치한다.'
like 'ab\\cd\%' escape '\' #abcd만 허용
SQL
복사
Ordering the Display of Tuples
SQL은 Relation에 있는 Tuple의 출력될 순서를 사용자가 제어할 수 있도록 한다.
order by : 튜플이 정렬된 순서로 나타나도록 한다.
물리학과의 모든 교수를 알파벳 순서로 나열하면 다음과 같이 작성한다.
select name
from instructor
where dept_name = 'Physics'
order by name;
SQL
복사
기본적으로 order by 절은 오름차순으로 항목을 나열한다.
•
정렬 순서를 명시하기 위해서
◦
desc : 내림차순
◦
asc : 오름차순
Where Clause Predicates
SQL은 between 비교 연산자를 제공한다.
select name
from instructor
where salary between 90000 and 100000;
SQL
복사
tuple 비교도 가능
select name, course_id
from instructor, teaches
where (instructor.ID, dept_name) = (teaches.ID, 'Biology');
SQL
복사
Set Operations
•
Union : 합집합
•
Intersect : 교집합
•
Except : 차집합
다음과 같은 Set Operation은 기본적으로 duplicates를 제거한다.
따라서 중복을 허용하고 싶다면 all을 붙이자.
Union은 앞에있는 Relation과 뒤에있는 Relation이 같은 attribute와 타입을 가져야 함.
Fall 2017에 개설된 course 또는 Spring 2018에 개설된 course를 구하라.
(select course_id from section where sem = 'Fall' and year = 2017)
union
(select course_id from section where sem = 'Spring' and year = 2018)
SQL
복사
Fall 2017에 개설된 course 그리고 Spring 2018에 개설된 course를 구하라.
(select course_id from section where sem = 'Fall' and year = 2017)
intersect
(select course_id from section where sem = 'Spring' and year = 2018)
SQL
복사
Fall 2017에 개설되었지만 Spring 2018에 개설되지 않은 course를 구하라.
(select course_id from section where sem = 'Fall' and year = 2017)
except
(select course_id from section where sem = 'Spring' and year = 2018)
SQL
복사
Null Values
Null값은 실제 값이 없을 수도 있고, 값이 알려지지 않을 수도 있음.
•
null의 사칙연산의 값은 null이다.
◦
null + 5 = null
•
null은 테이블의 조건에서도 찾을 수 있다.
select name
from instructor
where salary is null
SQL
복사
•
null과의 모든 비교 결과는 unknown이다.
◦
5 < null
◦
null < null
◦
null = null
Null Values and Three Valued Logic
Aggregate Functions
•
avg : average value
•
min : minimum value
•
max : maximum value
•
sum : sum of values
•
count : number of values
Computer Science department의 교수의 평균연봉을 구하라.
select avg(salary)
from instructor
where dept_name = 'Comp.Sci.';
SQL
복사
2018 봄학기에 강의를 여는 교수의 총합 넘버를 구하라.
select count(distinct ID)
from teaches
where semester = 'Spring' and year = 2018
SQL
복사
Computer Science department의 교수의 평균연봉을 구하라.
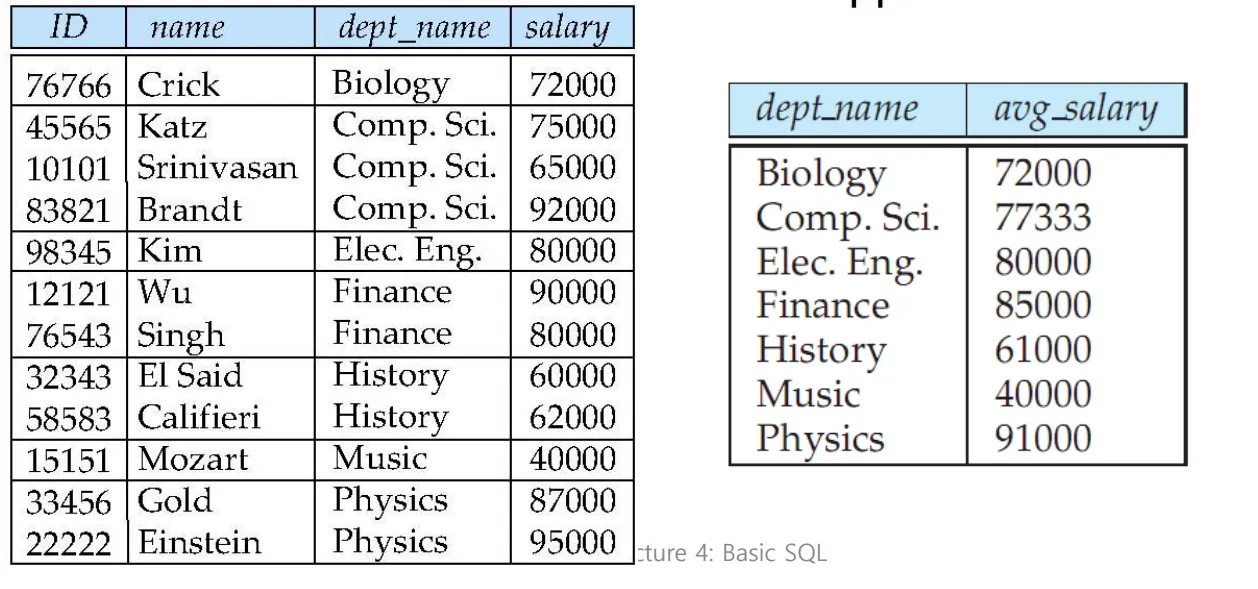
Group By
select dept_name, avg(salary)
from instructor
group by dept_name;
SQL
복사
결과 값은 다음과 같이 나타난다.
Having Clause
select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name
having avg (salary) > 42000;
SQL
복사
group by 명령어가 불리고 난 후(그룹이 형성된 이후) 조건을 체크한다.
where은 그룹이 형성되기 이전 조건을 체크한다.Null Values and Aggregates
Nested Subqueries
서브쿼리는 (select-from-where) 표현 안에 있는 또다른 (select-from-where)표현의 쿼리다.
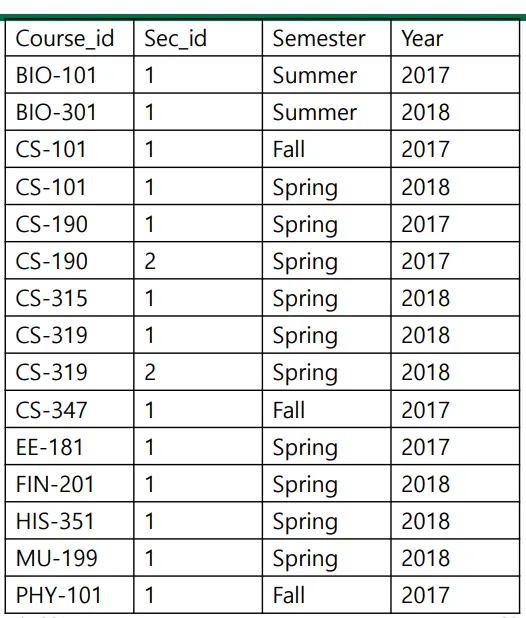
Example Query : in
select distinct course_id
from section
where semester = 'Fall' and year = 2017 and course_id in
(select course_id from section where semester = 'Spring' and year = 2018)
SQL
복사
in = and라고 봐도 무방할듯?
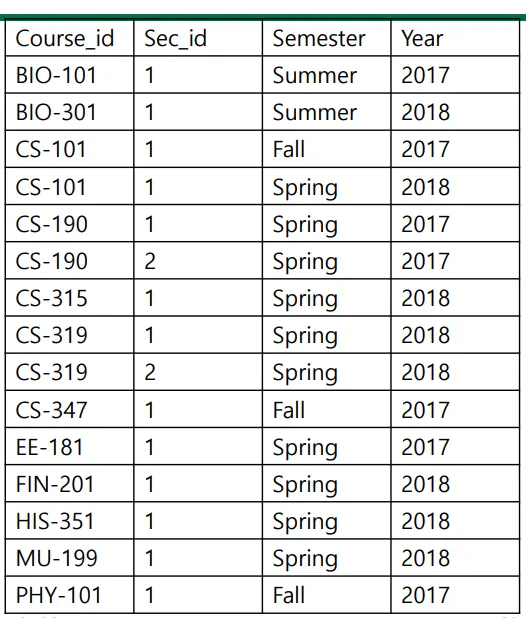
Example Query : not in
select distinct course_id
from section
where semester = 'Fall' and year = 2017 and course_id
not in
(select course_id from section where semester = 'Spring' and year = 2018)
SQL
복사
in = and라고 봐도 무방할듯?
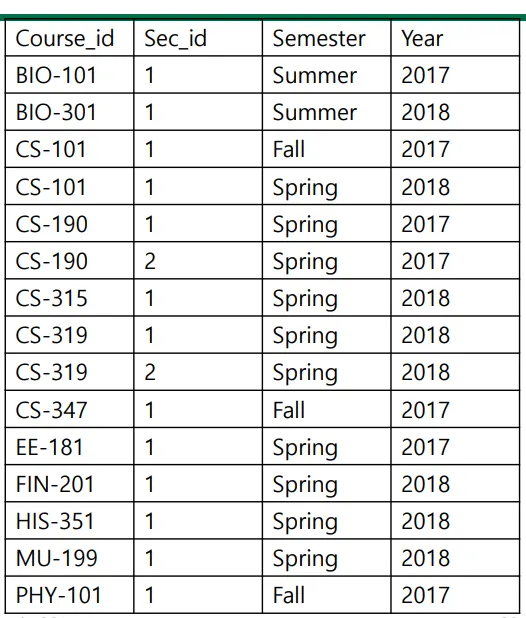
Example Query : not in
select count (distinct ID)
from takes
where (course_id, sec_id, semester, year) in
(select course_id, sec_id, semester,year
from teaches
where teaches.ID = 10101);
SQL
복사
in = and라고 봐도 무방할듯?
Set Comparison
•
select distinct T.name
from instructor as T, instructor as S
where T.salary > S.salary and S.sept_name = 'CSE';
SQL
복사
이 쿼리는 다음과 같이 나타낼 수 있다.
select name
from instructor
where salary > some (select salary
from instructor
where dept_name = 'CSE');
SQL
복사
Definition of Some Clause
5 < some(0, 5, 6) = true (tuple의 값 중 6은 5<6을 만족시킴)
5 < some(0, 5) = false
Definition of all Clause
Test for Empty Relations
exists는 서브쿼리가 nonempty일 경우 true를 반환한다.
r ≠ Ø
Correlation Variables
select course_id
from section as S
where semester = ’Fall’ and year= 2017 and
exists (select *
from section as T
where semester = ’Spring’ and year= 2018
and S.course_id= T.course_id); #Not necessary part;;
SQL
복사
Find all courses taught in both the
Fall 2017 semester and in the Spring 2018 semester
section이 본 쿼리에서 S로 정의되고, 서브쿼리에서 T로 정의됨을 주목하라.
서브쿼리와 본 쿼리가 같은 Relation에 대해서 연산을 하고자 하는데, 두 쿼리에서 찾은 값을 구분을 해야하므로, 다른 이름으로 Rename하는 것을 볼 수 있다.
•
Correlated subquery
•
Correlation name or correlation variable
Not Exists
select distinct S.ID, S.name
from student as S
where not exists ( (select course_id
from course
where dept_name = ’Biology’)
except
(select T.course_id
from takes as T
where S.ID = T.ID));
SQL
복사
만약 exists문 안의 내용이 true라면 → exist의 값은 true, not exist의 값은 → false
not exists (A - B)
exists (B union not A)
Test for Absence of Duplicate Tuples
select T.course_id
from course as T
where unique (select R.course_id
from section as R
where T.course_id= R.course_id
and R.year = 2017);
SQL
복사
중복된 tuples가 있는지를 확인하기 위해 unique 오퍼레이터가 사용된다.
•
서브쿼리 안에 중복된 tuples가 있는지 확인하고, 결과가 empty set이라면 true를 리턴
◦
Empty set또한 true로 간주한다.
Subqueries in the From Clause
from에서 나오는 서브쿼리
select dept_name, avg_salary
from (select dept_name, avg (salary) as avg_salary
from instructor
group by dept_name)
where avg_salary > 3000000;
SQL
복사
a.k.a.
select dept_name, avg_salary
from (select dept_name, avg (salary)
from instructor group by dept_name)
as dept_avg (dept_name, avg_salary) where avg_salary > 3000000;
SQL
복사
With Clause
임시적인 View를 제공한다. (임시적이기 때문에 저장되지 않음 → 쿼리가 끝나면 그냥 날아감 푱)
with dept_total (dept_name, value) as
(select dept_name, sum(salary)
from instructor
group by dept_name), #dept_total View
dept_total_avg(value) as
(select avg(value)
from dept_total) #dept_total_avg View
select dept_name
from dept_total, dept_total_avg
where dept_total.value >= dept_total_avg.value;
SQL
복사
Scalar Subquery
싱글 value가 예상되는 쿼리에 쓰는 것
1차원 벡터 = 스칼라 ⇒ 1개 밸류 = 스칼라 서브쿼리?
select dept_name,
(select count(*)
from instructor
where department.dept_name = instructor.dept_name)
as num_instructors
from department;
SQL
복사
Modification of the Database
Deletion
Insertion
Updates
Case Statement for Conditional Updates
Next chapter