
Previous chapter
Join Expressions
Joined Relations
두 Relation을 가지고 또다른 Relation을 창출하는 오퍼레이터
•
2개 이상의 테이블로부터 rows를 조합한다.
•
Natural Join
•
Inner join
•
Outer Join
Natural Join in SQL
select name, course_id
from students, takes
where student.ID = takes.ID;
SQL
복사
다음 쿼리와 같다.
select name, course_id
from student natural join takes
SQL
복사
일반화하면 다음과 같다.
select A1, A2, An
from r1 natural join r2 ... natural join rn
where P;
SQL
복사
attribute의 name을 체크하여 동일한 항목이 있는지 체크한다.
name을 체크
Danger in Natural Join
동일한 attribute name을 모두 체크하기 때문에 특정 조건만 체크하고 싶은 경우 의도하지 않은 정보가 출력될 수 있다.
select name, title
from student natural join takes natural join course;
SQL
복사
student와 takes간 natural join을 진행한 relation에 course를 natural join을 진행하면 course_id와 dept_name 모두 체크가 된다.
모든 공통된 attribute간 일치하는게 있는지 체크하기 때문에 course_id만 같은게 있는지 체크하고 싶다면 아래와 같이 코드를 짜야한다.
select name, title
from student natural join takes, course
where takes.course_id = course.course_id;
SQL
복사
Natural Join with Using Clause
using 키워드를 사용해서 특정 attribute를 지정해줄 수 있다. (using이 없다면 default option)
select name, title
from (student natural join takes) natural join course using (course_id)
SQL
복사
Join Conditions
•
on : Inner Join
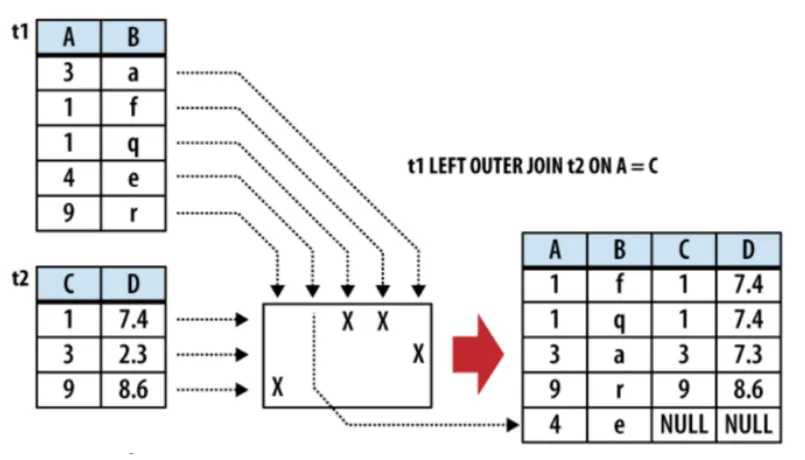
select *
from student join takes on (student_ID = takes_ID)
SQL
복사
on 키워드를 사용한 위 코드는 다음과 같다.
select *
from student, takes
where student_ID = takes_ID;
SQL
복사
inner Join은 조건에 해당하지 않으면 버려진다.
4와 e가 t2에 없기 때문에 버려진
Outer Join
보존하고 싶은 데이터를 보존하는 형태.
빈 데이터는 null값을 기본으로 쓴다.
Left Outer Join
Right Outer Join
Full Outer Join
Join Types and Conditions
Join Condition
•
두 relations에서 어떤 tuples가 매칭되게 할 지 정의
Join types
•
ordering Issues??? 다음시간에 계속…..
View
View Definitions and Use

instructor의 정보는는 필요하지만 그 중 salary 정보는 필요하지 않은 사람을 생각해보자.
salary 없이 instructor의 View를 생성
create view faculty as
select ID, name, dept_name
from instructor
SQL
복사
Biology Department의 instructor을 모두 선택
select name
from faculty
where dept_name = 'Biology‘
SQL
복사
Department Salary Total의 View를 생성
create view departments_total_salary(dept_name, total_salary) as
select dept_name, sum (salary)
from instructor
group by dept_name;
SQL
복사
Using Other Views
v2라는 View를 만들고 v2로부터 새로운 View v1을 뽑아내고 싶다고 할 때, v1은 v2에 직접적으로 의존된다(depend directly)고 한다.
create view physics_fall_2017 as
select course.course_id, sec_id, building, room_number
from course, section
where course.course_id = section.course_id
and course.dept_name = 'Physics'
and section.semester = 'Fall'
and section.year = '2017’;
SQL
복사
create view physics_fall_2017_watson as
select course_id, room_number
from physics_fall_2017
where building= 'Watson';
SQL
복사
physics_fall_2017_watson은 physics_fall_2017에 depend directly한다.
아까 view는 일종의 서브쿼리 → 변수화에 가깝다고 했는데 위 코드를 아래와 같이 바꿀 수 있을 것이다.
create view physics_fall_2017_watson as
select course_id, room_number
from (select course.course_id, building, room_number
from course, section
where course.course_id = section.course_id
and course.dept_name = 'Physics'
and section.semester = 'Fall'
and section.year = '2017')
where building= 'Watson';
SQL
복사
따라서 다음과 같이 변환될 수 있을 것이다.
repeat
e(1)안에 relation v(i)를 찾아라
v(i)를 정의하는 것으로 v(i)를 대체해라
until e1에 View가 더이상 없을때까지
SQL
복사
Materialized Views
임시적으로 View를 저장하겠다! View들이 많이 쓰일 것이고, select문이 오버헤드가 크다고 판단하는 경우 메모리나 스토리지에 저장되는 경우도 있음.
단, Materialized Views는 본체 Relation이 업데이트가 되면 정보가 업데이트가 자동으로 되지 않기 때문에, 본체 Relation이 업데이트 될 때마다 View를 업데이트해서 유지보수를 해줘야 한다. 이제 Update의 방법을 자.
Update of a View
instructor로부터 비롯된 faculty View에 새로운 tuple을 넣는다고 가정하자.
insert into faculty
values('30765'm 'Green', 'Mist');
SQL
복사
두 가지 방법이 있을 것이다.
Some Updates Cannot be Translated Uniquely
create view instructor_info as
select ID, name, building
from instructor, department
where instructor.dept_name= department.dept_name;
SQL
복사
insert into instructor_info
values ('69987', 'White', 'Taylor');
SQL
복사
위에서 보면 instructor와 department에 dept_name이 같은 것을 확인하고 View를 짰다.
dept_name
And Some Not at All
View Updates in SQL
따라서 SQL에서 View 업데이트는 다음과 같은 경우에만 허락하도록 한다.
그냥 View는 읽는 용도로만 쓰자.
Transaction
여러개의 연산을 하나의 연산으로 취급하는 친구
begin; op1; op2; commit;
SQL
복사
이때 두 오퍼레이션이 모두 잘 실행되던가, 둘 모두 reject되고 끝나던가를 보장한다.
따라서 Transaction은 다음과 같은 상태중 하나로 모두 끝나야 한다.
결국 Transaction은 Atomic하여야 한다.
•
모두 완료되거나 롤백하여 절대로 일어나지 않은 것 처럼 해야 한다.
Transactions의 Isolation
Integrity Constraint
Constraints on a Single Relation
•
not null
•
primary key
•
unique
•
check(P)
Not Null Constraints
name varchar(20) not null
budget numeric(12,2) not null
SQL
복사
Unique Constraints
The Check Clause
create table section
(course_id varchar (8),
sec_id varchar (8),
semester varchar (6),
year numeric (4,0),
building varchar (15),
room_number varchar (7),
time slot id varchar (4),
primary key (course_id, sec_id, semester, year),
check (semester in ('Fall', 'Winter', 'Spring', 'Summer')))
SQL
복사
Referential Integrity
????????????
Cascading Actions in Referential Integrity
create table course (
(…
dept_name varchar(20),
foreign key (dept_name) references department
on delete cascade
on update cascade,
. . .)
SQL
복사
cascade대신 set null이나 set default 값으로 설정될 수도 있다.
Integrity Constraint Violation During Transactions
create table person (
ID char(10),
name char(40),
mother char(10),
father char(10),
primary key ID,
foreign key father references person,
foreign key mother references person)
SQL
복사
constraint violation없이 tuple insert를 하려면 어떻게 해야하는가?
•
father, mother을 null기본값으로 설정하고 모든 사람을 넣은 뒤 업데이트 하면 된다.
Complex Check Conditions
Assertions
SQL Data Types and Schemas
Built-in Data Types in SQL
•
date : ‘yyyy-mm-dd’
•
time : ‘HH:MM:SS’
•
timestamp : date + time
•
interval 시간의 간격 ‘1’ day
Large-Object Types
큰 파일은 large-object로 구성한다.
파일의 크기가 너무 크다면 스토리지에 따로 저장해놓고 위치를 지정해주는 경우가 있다.
User-Defined Types
create type Dollars as numeric (12,2) final
SQL
복사
create table department
(dept_name varchar(20),
building varchar (15),
budget Dollars);
SQL
복사
Domains
create domain person_name char(20) not null
SQL
복사
example:
create domain degree_level varchar(10)
constraint degree_level_test
check (value in ('Bachelors', 'Masters', 'Doctorate'));
SQL
복사
Index Creation
Authorization
데이터베이스 일부에 대한 여러 형태의 권한을 사용자에게 할당할 수 있다.
•
Read - 데이터를 읽을 권한 (reading 가능, modification은 불가능)
•
Insert - 새로운 데이터를 삽입할 권한 (Insert 가능, modification은 불가능)
•
Update - 데이터를 갱신할 권한 (modification 가능, delete는 불가능)
•
Delete - 데이터를 삭제할 권한.
이런 유형의 권한을 특권(privilege)라 부른다.
릴레이션이나 뷰와 같은 DB 일부에 이런 유형의 privilege를
전체 사용자에게 부여하거나
부여하지 않거나(금지하거나)
일부만 부여할 수 있다.
데이터에 대한 권한과 함께, 릴레이션의 생성, 수정, 삭제와 같은 데이터베이스 스키마 변경 권한도 사용자에게 부여할 수 있다. 일부 형태의 권한을 소유한 사용자는 자신의 권한을 타 사용자에게 전달하거나 이전에 부여된 권한을 철회할 수 있다.
•
Index - 인덱스의 생성과 삭제
•
Resources - 새 Relation의 생성
•
Alteration - Relation의 새 Attribute에 대한 추가 혹은 삭제
•
Drop - Relation의 삭제
Authorization Specification in SQL
grant문은 권한을 부여하는 용도로 사용된다.
grant <privilege list> on <relation or view> to <user list>
SQL
복사
<user list> 에 들어올 수 있는 파라미터
•
user-id
•
public : 모든 유저에게 특권을 부여한다.
•
A role : 역할?
Privileges in SQL
•
select : Relation에 접근/읽기 혹은 view를 이용해 질의할 수 있다.
grant select on <relation> to U1, U2, U3...
SQL
복사
•
insert : tuple을 집어넣는 능력
•
Update : SQL update statement를 이용해 업데이트하는 능력
•
delete : 튜플을 삭제하는 능력
Revoking Authorization in SQL
revoke문은 특권을 폐지하는 지시문이다.
revoke <privilege-list> on <relation or view> from <user list>
SQL
복사
•
<privilege-list>
◦
모든 권한을 박탈하려면 all 키워드를 쓸 수 있다.
◦
public?
•
같은 특권이 다른 유저에게 두번 할당되었을 경우, 박탈 후에도 특권이 유지될 수 있다.
Roles
역할 (Role)은 다양한 유저로부터 각 유저가 DB에 접근, 갱신할 수 있는 범위를 구별하기 위한 방법이다.
역할 생성
create role <name>
SQL
복사
role이 생성된 후에 다음과 같이 유저에게 role을 부여할 수 있다.
grant <role>to <users>
SQL
복사
A → B 상태의 롤에서 A를 삭제했을때 B라는 롤이 효용이 없을텐데 B도 자동적으로 삭제되는가?
프로세스로 따지면
Next chapter