
Previous chapter
Failure Classification
•
Transaction Failure : 트랜잭션이 실행이 안됐을 경우 복구를 고려해야하는 상황
◦
Logical error : 트랜잭션 내부의 conflict 등 에러 조건에 의해서 완수되지 못할 때 발생하는 에러.
◦
System error : 트랜잭션이 수행은 됐으나 시스템 단계에서 에러가 일어난 경우(deadlock 등)
•
System Crash : 데
•
Disk Failure : 디스크에 정보를 저장해야하는데 디스크가 망가진 경우
Recovery Algorithms
•
트랜잭션이 수행될때,
Data Access
•
Physical Block : 스토리지에 있는 데이터
•
Buffer Block : 메모리에 있는 데이터
디스크에서 바로 데이터를 옮길 수 없기 때문에 반드시 메모리를 거쳐야 한다.
이를 위해 DB에서는 내부적인 연산을 준비하는데 input과 output이다.
•
input : 블럭을 메인 메모리로 전송
•
ouput : 버퍼에 있는 데이터를 디스크에 저장
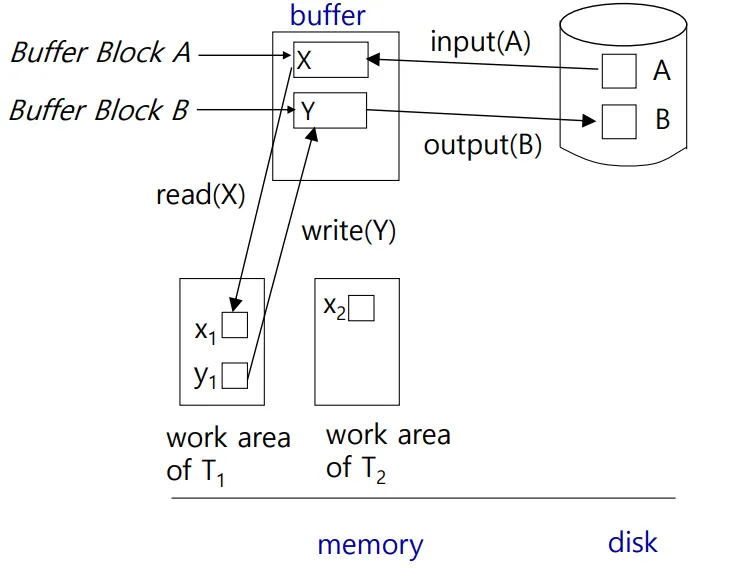
commit할때만 데이터를 올리겠다던지, 올리더라도 참고할 수 있는 시점의 지표를 만들어 접근을 제어할 수 있음.
만약 버퍼에 데이터가 없다면 디스크에서 버퍼로 데이터를 반드시 읽어와야 한다.
쓰기연산은 반드시 데이터를 보낼 필요가 없음.???
각 트랜잭션은 로컬 카피본을 가지고 있다.
DB
Recovery and Atomicity
Atomicity를 어떻게 보장할 것인가
Shadow copy : old하지만 consistent한 데이터 카피를 가지고 있음.
update를 실행하면 새로운 카피를 생성한다.
만약 실패하더라도 문제가 안생김
shadow카피에서 각종 연산을 수행한 후, 포인터를 변환한다.
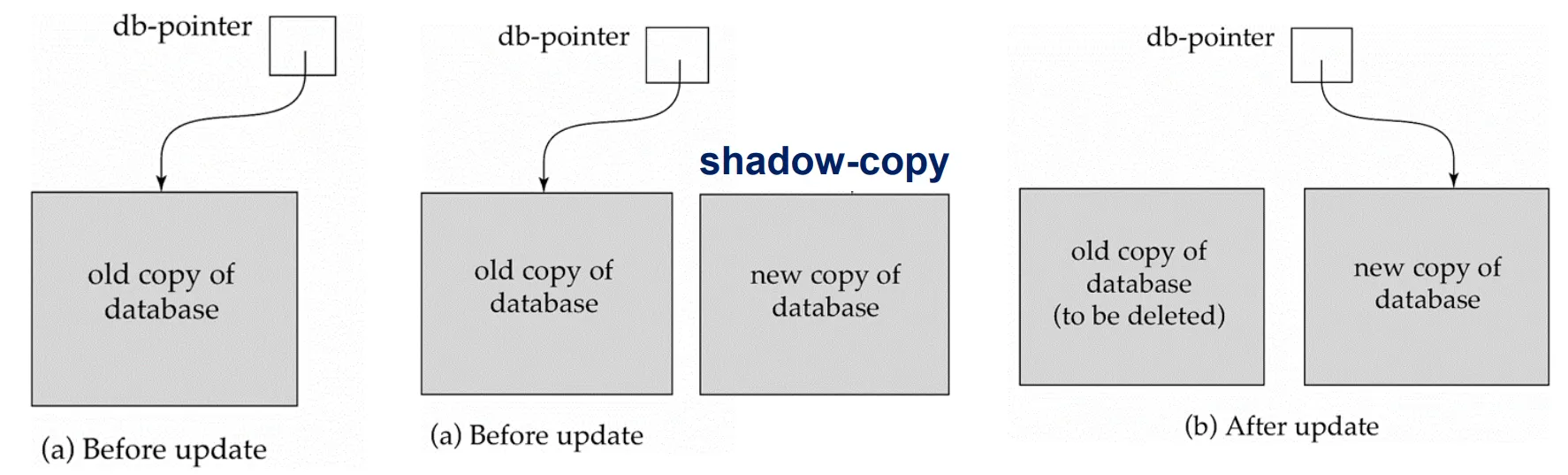
Shadow Paging
•
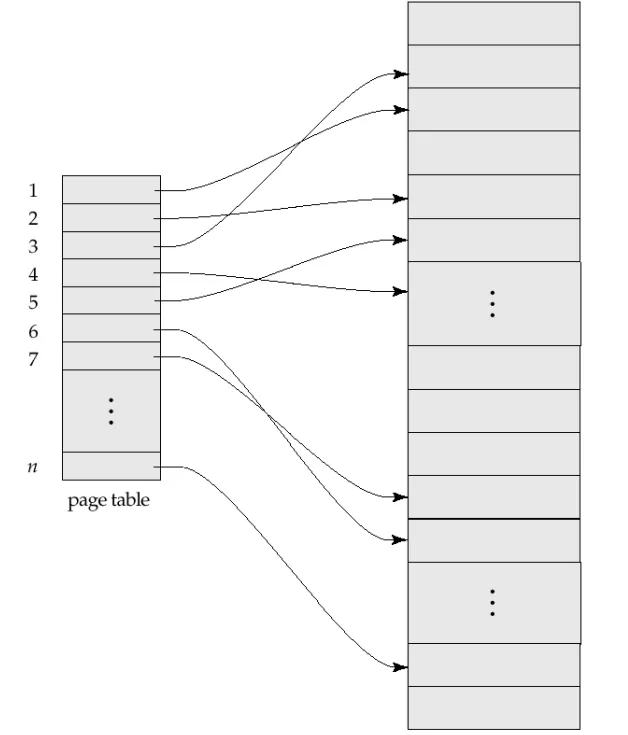
페이지 단위를 관리해야함. 페이지가 여러개면 포인터도 여러개가 있어야함.
◦
그 포인터를 관리하는 페이지 테이블을 만들어야하는데, 지금 기본적으로 사용하는 현재 페이지 테이블과 새로운 버전의 페이지 테이블이 필요함.
•
하나는 수정하는데 쓰고 하나는 복구용으로 사용함.
Example of Shadow Paging
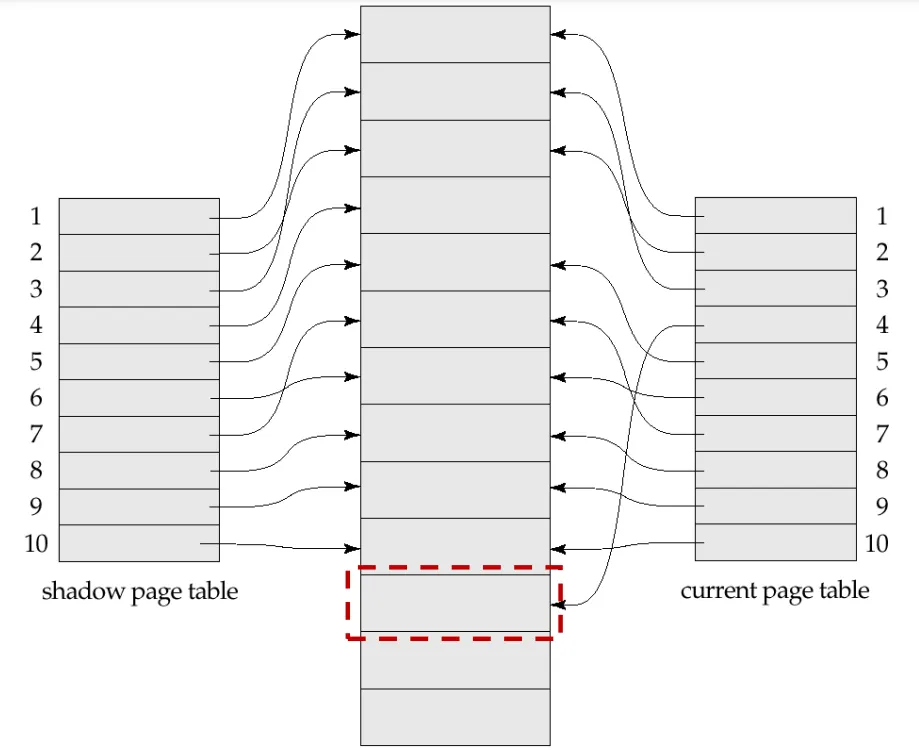
데이터를 기록하고 포인터를 옮기고 페이지 테이블을 갱신한다.
페이지 테이블은 디스크에 저장되어야 한다.
•
트랜잭션을 커밋하기 위해서는
1.
모든 바뀐 페이지는 디스크에 기록을 해야하.
2.
현재 수정된 current page테이블을 기록해야함.
3.
만약에 새로 기록된 녀석이 잘 기록되었다면 최신 consistent기록을 가지고 있는 것이기 때문에 shadow 페이지를 변경해준다.
시스템이나 트랜잭션이 멈추더라도 따로 해야할 액션이 없는 것이 최대 장점. current 페이지를 버리고 shadow페이지만 보면 되기 때문에 recovery 연산이 추가적으로 필요한게 아님.
포인팅되지 않는 페이지 테이블은 주기적으로 스캔해서 가비지 콜렉팅을 해줘야한다.
단점
•
전체 페이지를 복사하는 건 굉장히 비싼 작업
•
커밋 오버헤드가 커짐.
◦
업데이트된 페이지 모두와 페이지 테이블을 플러쉬해줘야함.
•
매번 복사&기록이 발생하므로 단편화 현상이 발생할 수 있다.
•
새로운 페이지를 업데이트 했을 경우, 가비지가 발생하여 주기적으로 수거해야하는 오버헤드가 발생한다.
•
동시에 트랜잭션이 동작하기 어려운 환경이다.
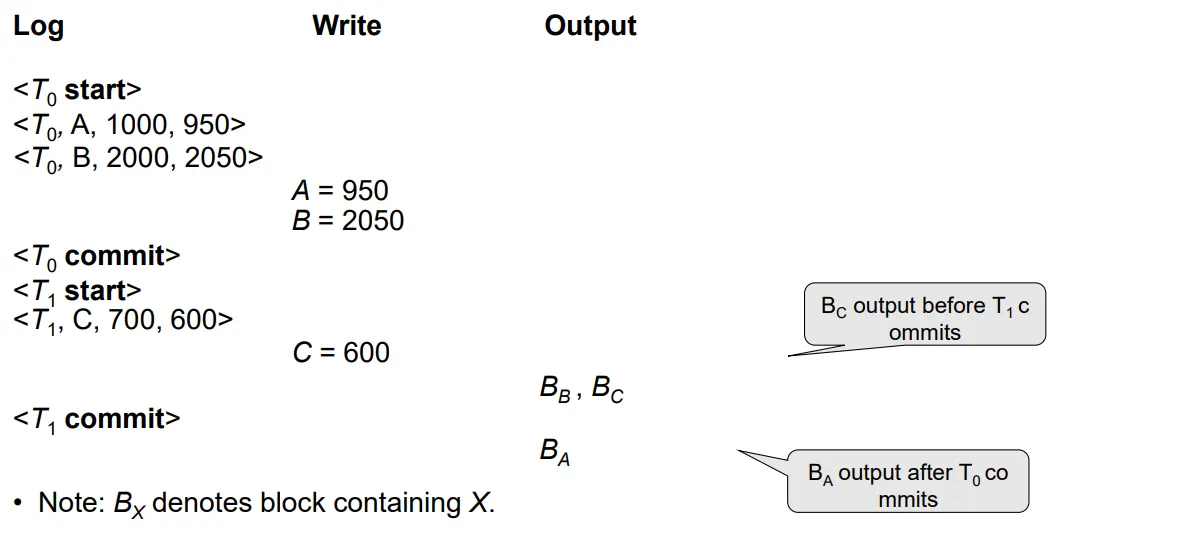
Log-Based Recovery
<Ti start> : 트랜잭션 시작
<Ti, X(변수), V1(예전 value), V2(현재 value)>
Ti가 끝났을 경우 <Ti commit>을 해줘야함.
commit의 유무를 기준으로 리커버리를 결정한다.
Immediate Database Modification
즉시 수정 기법은
로그 레코드를 데이터 베이스를 건드리기 전에 작성을 완료해야한다.
Deferred
Concurrency Control and Recovery
동시다발적으로 Transaction이 수행된다면 머리가 아플 것이다.
하나의 머시에서 하나의 디스크, 하나의 버퍼, 하나의 로그를 가지고 있다.
Undo and Redo Operation
undo(Ti) : start만 포함, commit도 없고 abort도 없을 경우 효과 발동.
Recovering from Failure
Checkpoints
로그가 쭉 있을 때 시스템 크래시가 발생했다면 로그의 양이 기하급수적으로 늘어날 것.
체크포인트를 활용해 확인해야하는 로그의 개수를 줄이자.
Example of Checkpoints
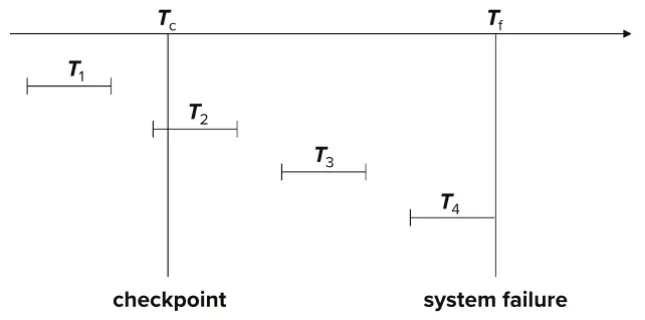
T2 주의. 체크포인트 이전에 커밋이 완료되지 않은 트랜잭션 모두 재검사의 대상이 된다.
Next chapter